Bub
Bub
History of memory management
Bub
Bub is another general purpose agent (similar to openclaw). It implements an interesting memory management strategy using “tape”. Tape is basically a series of events chained together, and in single user world, it’s simply the conversation history. Tape is initially created for multi-team work. According to podcast 「捕蛇者说」, the creator of Bub said that the incentive is to improve agent performance in a group chat of hundreds of users. Tools like openclaw is initially designed for single user following a single thread.
Design
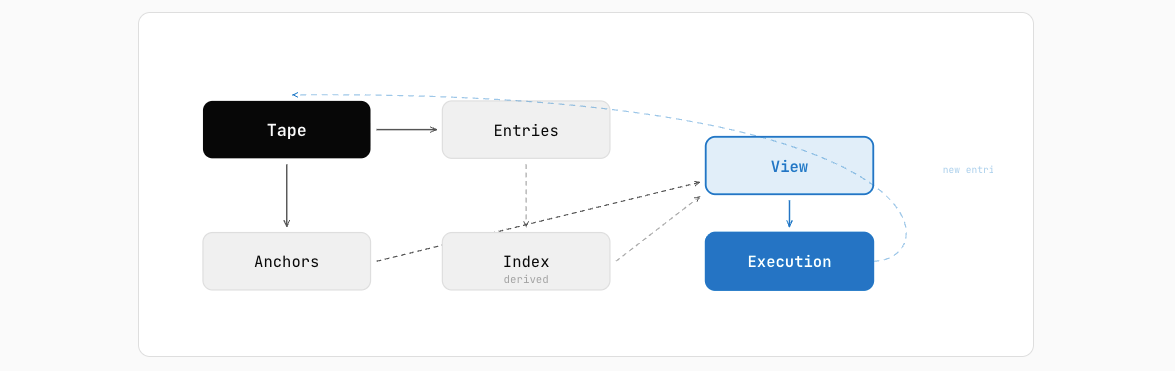 Four key concepts in the design of bub (according to official document):
Four key concepts in the design of bub (according to official document):
- Tape: a chronological sequence of facts
- Entry: a immutable fact record
- Anchor: a checkpoint for state record
- View: task-oriented assembled context window
The tape is append only, and only view is changed in different conversation contexts.
The creator of Bub also mentioned that he worked in database company for long time, so it feels like the design of tape is very similar to binlog in database.
Anchor
Although tape is chronically continuous, it is logically divided by “anchors”, which marks the start of a task. For example, an anchor can mark the start of “discovery” task, where the agent run tools to fetch information from web browsers, read local files, use mcp, etc. All these tool calls and self reflection are appended after the “discovery” anchor. After discovery, another anchor for “implementation” can be added, so that file edits and test runs are separated from previous events. Two obvious benefits of this design are
- You can split the pure events (like discovery, where no change is introduced to local) and impure events (like implementation, where changes are introduced), so checkpointing, branching and rewinding can be done pretty easily.
- The auditability and observabiltiy comes for free, because all events are structured and persisted. Nothing will be lost.
Handoff
Transition from one task to another triggers a “handoff”. The model itself decides when to call the handoff tool to trigger a handoff, which creates an anchor that summarizes the current status with references to certain events.
@tool(context=True, name="tape.handoff")
async def tape_handoff(name: str = "handoff", summary: str = "", *, context: ToolContext) -> str:
"""Add a handoff anchor to the current tape."""
agent = _get_agent(context)
await agent.tapes.handoff(context.tape or "", name=name, state={"summary": summary})
return f"anchor added: {name}"
tape = llm.tape("support-session")
# Tape default context uses the latest anchor, so handoff first.
tape.handoff("network_issue", state={"owner": "tier1"})
out1 = tape.chat("Customer cannot connect to VPN. Give triage steps.", max_tokens=64)
print("reply1:", out1)
out2 = tape.chat("Also include DNS checks.", max_tokens=64)
print("reply2:", out2)
tape.handoff("billing_issue", state={"owner": "tier2"})
out3 = tape.chat("Customer asks for refund process.", max_tokens=64)
print("reply3:", out3)
If the model needs previous information, it can always search through the history by anchors.
@tool(context=True, name="tape.anchors")
async def tape_anchors(*, context: ToolContext) -> str:
"""List anchors in the current tape."""
agent = _get_agent(context)
anchors = await agent.tapes.anchors(context.tape or "")
if not anchors:
return "(no anchors)"
return "\n".join(f"- {anchor.name}" for anchor in anchors)
@tool(context=True, name="tape.search", model=SearchInput)
async def tape_search(param: SearchInput, *, context: ToolContext) -> str:
"""Search for entries in the current tape that match the query. Returns a list of matching entries."""
agent = _get_agent(context)
query = (
TapeQuery[AsyncTapeStore](tape=context.tape or "", store=agent.tapes._store)
.query(param.query)
.kinds(*param.kinds)
.limit(param.limit)
)
if param.start or param.end:
query = query.between_dates(param.start or "", param.end or "")
entries = await agent.tapes.search(query)
lines: list[str] = []
for entry in entries:
entry_str = json.dumps({"date": entry.date, "content": entry.payload})
if "[tape.search]" in entry_str:
continue
lines.append(entry_str)
return f"[tape.search]: {len(entries)} matches" + "".join(f"\n{line}" for line in lines)
A session is a collection of events, which is basically a “view” of the tape. Notice that events from different sessions can interleave with each other on the tape, since there is only one tape. The session is responsible for identifying all events it contains from the tape. By default, sessions are isolated from each other, but it is possible for cross convo
Comparative Study
Let’s do some thought expriment as to what is the strength and weakness of this tape system comparing with traditional emphemeral-session based agent:
KV Cache miss
One potential weakness for tape system is that if a dynamic context window can cause a lot of KV cache miss, thus burning tokens and increasing latency. A lot of token-efficiency algorithms(vLLM Paged Attention on server side, SGLang Radix tree on client side) can not be applied anymore, because the prefix are no longer the same. The traditional session based agent always has the fix prefix for each prompt, because it is always structured as system prompt-previous conversation-latest message. The first two parts are cached and not changed as new messages gets appended.
Context bloat
There are several popular ways to manage context bloat for complex problem:
- Compaction: summarize everything before, and use the summary as new starting point.
- Subagents fan out: split the task into multiple parallel agents that uses their own context window to tackle simpler problem.
In tradiational session based agent, all conversation is forwarded to LLM on each turn, so the context can grow pretty quickly. Most implementation just do a one-time compaction to reduce the context window pressue, inevitably losing information. On the other hand, one-time compaction only causes a KV cache miss, and then all subsequent turns are all cache hit again, so it’s probably more token efficient.
Since the tape system does not pull all history conversation into the view but only pull relevant ones by anchor, the context window pressue can be greatly reduced, since as the thread goes, the remote turns are churned.
The tape system provide great convenience for subagent system, since all context is preserved, and all agents, regardless of master agent or subagent, has the ability to see the whole picture. For traditional session based agent, each sub agent can only see its own history and the instruction given by the master agent. It’s hard to share context between multiple sub agents.
Questions unanswered
-
Is infinite message history actually makes sense? The anchor meta info is still going to bloat up context window at the end, just in a slower manner.
-
Is the model capable enough to determine when to search for the additional context through previous anchors not in the context?