WASM 101 | 二进制格式
Meta-Intro
WASM(WebAssembly)是一个虚拟指令集,具备了跨平台可移植性、简单性、出色的性能和安全性,在高性能/分布式计算/嵌入式中都有很大的前景(会取代Docker吗?)。
Intro
这篇博客中我们会探索 WASM 的一个重要部分:二进制文件格式。WASM 以二进制形式发布,二进制文件可以更高效且安全(至少比 JavaScript 这种脚本语言更难逆向工程 😉)。
WASM 二进制文件可以通过 WASM 编译器从其他编程语言(比如 C)编译而来。我们可以简单地从WasmFiddle获取 WASM 二进制文件:把示例程序(在 Appendix 中)copy paste,编译,然后下载 WASM 文件。
看看下载的fib.wasm文件里有啥:
~ » hexdump -C fib.wasm
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
00000010 01 7f 01 7f 60 00 01 7f 03 83 80 80 80 00 02 00 |....`...........|
00000020 01 04 84 80 80 80 00 01 70 00 00 05 83 80 80 80 |........p.......|
00000030 00 01 00 01 06 81 80 80 80 00 00 07 97 80 80 80 |................|
00000040 00 03 06 6d 65 6d 6f 72 79 02 00 03 66 69 62 00 |...memory...fib.|
00000050 00 04 6d 61 69 6e 00 01 0a d7 80 80 80 00 02 c6 |..main..........|
00000060 80 80 80 00 01 02 7f 41 01 21 02 02 40 20 00 41 |.......A.!..@ .A|
00000070 01 72 41 01 46 0d 00 20 00 41 7e 6a 21 00 41 01 |.rA.F.. .A~j!.A.|
00000080 21 02 03 40 20 00 41 01 6a 10 00 20 02 6a 21 02 |!..@ .A.j.. .j!.|
00000090 20 00 41 01 72 21 01 20 00 41 7e 6a 21 00 20 01 | .A.r!. .A~j!. .|
000000a0 41 01 47 0d 00 0b 0b 20 02 0b 86 80 80 80 00 00 |A.G.... ........|
000000b0 41 05 10 00 0b |A....|
000000b5
目前看起来乱七八糟的 🤨,我们一步一步分析。
Meta-info
首先,整个 wasm 文件会由 8 个字节的 meta-info 开始。
Magic Bytes
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
^ ^ ^ ^
前 4 个字节(即00 61 73 6d)叫魔术字节(magic bytes)。它们表明这个文件是 WASM 二进制表示。
Info“魔术字节”(Magic bytes)是文件中的特定字节序列,通常用于标识文件的格式或类型。这些字节序列通常位于文件的起始位置,并且是固定的。通过检查这些特定字节,软件可以迅速确定文件的类型,从而决定如何处理它。这种方法对于文件格式识别和安全性检查非常有用。
Version Number
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
^ ^ ^ ^
接下来的 4 个字节(即01 00 00 00)是版本号,表明该文件按照 WASM 1.0 规范编码。版本号用于确定 WASM 二进制文件所遵循的规范版本,以确保正确的解释和执行。这个文件的版本号指示文件符合 WASM 1.0 规范(2.0 已经 work in progress 了,但还没研究过 2.0 的规范)。
Sections
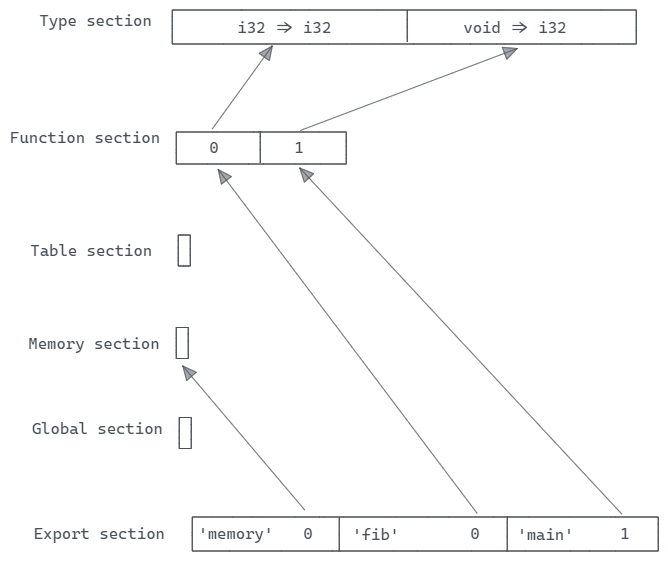
然后是实际内容部分。WebAssembly 模块可以分为 12 个部分:自定义(Custom)、类型(Types)、函数(Functions)、表(Tables)、内存(Memories)、全局变量(Globals)、元素段(Element Segments)、数据段(Data Segments)、启动函数(Start Function)、代码(Code)、导出(Exports)和导入(Imports)。一些部分是可选的,根据模块的具体需求来确定是否包含这些部分。
每个部分,都遵循以下结构:
- 1 个字节表示部分ID,标识该部分的类型。
- 4 个字节表示部分的字节数 N,指示该部分的内容占据了多少字节。
- 随后的 N 个字节包含了部分的具体内容。
Type
“Type section”(类型部分)包含了模块中所有函数的类型信息,也就是常说的函数签名(signature)。它列举了模块中所有函数的”(参数类型, 返回类型)“对。当一个函数需要声明其类型时,它只需指定一个索引,对应于”Type section”中的特定函数签名。
这种方式有助于减小 WebAssembly 模块的大小,因为函数可以重复使用现有的函数签名,而无需在每次声明函数时都重复列出完整的参数类型和返回类型。
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
^
01 是 ID,它表示了”Type section”(类型部分)的开始。
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
^ ^ ^ ^
8a 80 80 80 00 是数字 10 的 LEB-128 表示法,用于表示内容部分总共占 10 个字节。LEB-128(Little-Endian Base 128)使用可变长度的字节序列来表示整数,以减小整数表示的空间。
为啥要用这个非常迷惑的 LEB-128 表示法?
我们可以用固定数量的字节表示,例如在 C 语言中,整数用 4 个字节表示。
然而,如果要表示数字 6,其二进制表示为06 00 00 00,这意味着后三个字节被浪费了。如果要表示大于ff ff ff 7f的数字,例如2147483648,在这种情况下,4 个字节已经不够了。
这就是为什么需要变长表示法:更好的信息密度和更广泛的表示范围。
00000000 00 61 73 6d 01 00 00 00 01 8a 80 80 80 00 02 60 |.asm...........`|
^ ^
00000010 01 7f 01 7f 60 00 01 7f 03 83 80 80 80 00 02 00 |....`...........|
^ ^
接下来 10 个字节表示了”Type section”中的实际类型信息。其中,02表示类型部分包含两个元素(即总共有两种函数类型)。60 表示这个元素是一个”function type (➡️)“。接下来的 01 表示参数数量为 1,因此我们读取另一个字节 7f 以获取这个单一参数的类型,其中 7f 代表 i32 (➡️)。
读完了所有输入参数,我们可以继续读取返回值的数量:01,并且其类型也是 7f。因此,这个元素上定义了一个函数类型 i32 => i32,这就是我们的 fib 函数的类型 😀!
这种方式使得 WebAssembly 能够有效地定义函数的参数和返回类型,有助于正确解释和执行 WebAssembly 模块中的函数。
同理,下一个函数类型是void => i32。输入参数的长度为0,而只有有一个输出参数,类型为 i32。这就是我们的main函数的类型。

Import
“Import section”(导入部分)存储了导入信息,ID为2。导入信息包括导入的模块名称(module name)、导入的名称(name)以及导入描述(description)。WebAssembly支持四种类型的导入:函数、表、内存和全局变量。这个例子中没有Import section,我们可以通过下面的Export section来看。
Function
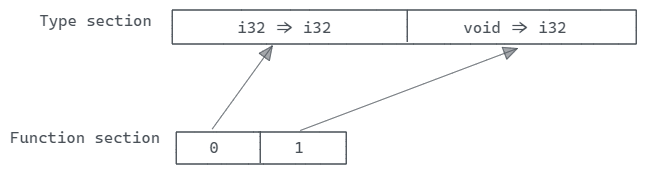
“Function section”(函数部分)包含了所有函数的声明,ID为3。可以理解为一个数组,数组中的条目是指向”Type section”数组的索引。
“Type section”存储函数的签名,“Code section”存储函数的实际实现,而”Function section”将它们两者关联在一起。
00000010 01 7f 01 7f 60 00 01 7f 03 83 80 80 80 00 02 00 |....`...........|
^ ^ ^ ^ ^ ^ ^ ^
00000020 01 04 84 80 80 80 00 01 70 00 00 05 83 80 80 80 |........p.......|
^
03 表示了”Functions section”(函数部分)的ID。接下来的 83 80 80 80 00 表示数字 3,指示了接下来的内容长度为3。紧接着的 02表示有两个函数(fib 和 main)。00 和 01 分别是类型部分的索引,意味着第一个函数具有类型 i32 => i32,而第二个函数具有类型 void => i32。
Table
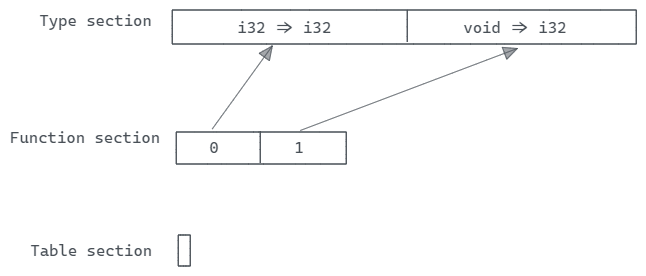
“Table section”(表部分)一系列的表。表是某个特定引用类型的数组(可以是函数引用或外部引用,即运行时提供的引用)。表可以在运行时扩展大小,因此可以指定大小的限制。最小值是必选的,而最大值是可选的。
00000020 01 04 84 80 80 80 00 01 70 00 00 05 83 80 80 80 |........p.......|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^
04 表示”Table section”(表部分)的部分ID,并且这个部分占用了4个字节。01 表示只有一个表条目。70 表示这个表的类型是也就是函数引用(➡️)。接下来的两个 00 分别表示大小限制标志(limit flag)和初始大小(limit initial)➡️。大小限制标志指示表是否具有最大大小限制,而初始大小表示表的最小大小。
综上,我们有一个表,用于存储函数引用,最小大小为0,没有最大大小限制。
Memory
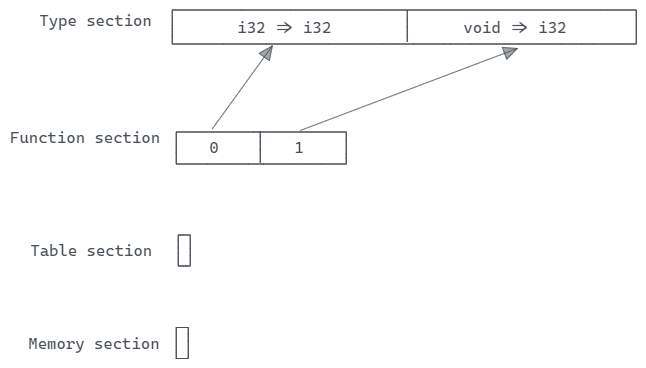
“Memory section”(内存部分)定义了线性内存,包含了原始未解释字节。线性内存可以通过”Data section”(数据部分)进行初始化,它还可以在运行时扩展,并具有大小限制。
00000020 01 04 84 80 80 80 00 01 70 00 00 05 83 80 80 80 |........p.......|
^ ^ ^ ^ ^
00000030 00 01 00 01 06 81 80 80 80 00 00 07 97 80 80 80 |................|
^ ^ ^ ^
05 表示”Memory section”(内存部分)的部分ID,这个部分占用了3个字节。与之前的”Table section”相似,这里也只有一个内存向量,没有最大大小限制,并且具有最小大小为1。
Global
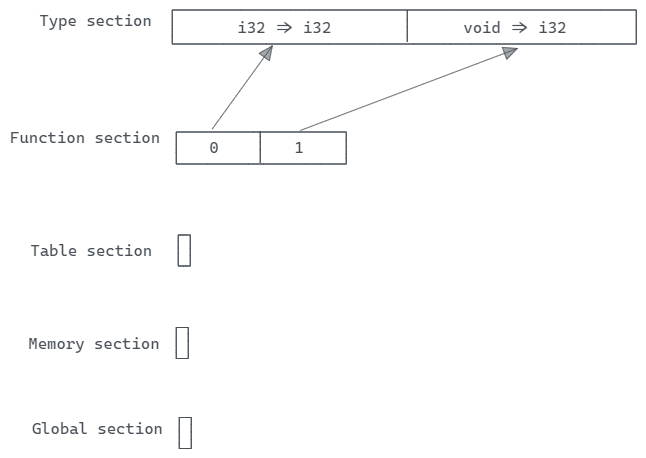
“Global variable section”(全局变量部分)定义了一个全局变量的数组。每个全局变量存储给定全局类型的单个值,并指定全局变量是只读还是可写的。每个全局变量都使用常量初始化表达式(constant initializer expression)来进行初始化。
00000030 00 01 00 01 06 81 80 80 80 00 00 07 97 80 80 80 |................|
^ ^ ^ ^ ^ ^ ^
在上面的例子中,可以看到ID是06,总长度为1,表示有一个字节。00表示这个数组的长度是0,也就是说没有全局变量。
Export
“Export section”(导出部分)定义了一组导出项,这些导出项在模块实例化后成为对宿主环境可访问的接口。每个导出项由一个名称(name) 和一个 导出描述(description) 组成,导出描述可以是一个指向函数、表、内存或全局变量的索引(只要提供索引就行啦,因为数据都在本模块内)。
导出使得WebAssembly模块可以向宿主环境公开特定的接口,以便宿主环境可以与模块进行交互。这些导出项可以包括函数、表、内存或全局变量的引用,使宿主环境能够调用模块中的函数、访问模块中的数据结构等。
00000030 00 01 00 01 06 81 80 80 80 00 00 07 97 80 80 80 |................|
^ ^ ^ ^ ^
00000040 00 03 06 6d 65 6d 6f 72 79 02 00 03 66 69 62 00 |...memory...fib.|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
00000050 00 04 6d 61 69 6e 00 01 0a d7 80 80 80 00 02 c6 |..main..........|
^ ^ ^ ^ ^ ^ ^ ^
07 表示”Export section”(导出部分)的ID,97 80 80 80 00表示这个部分占用了23个字节。03 表示有3个全局变量,而后面的 06 表示字符串 ‘memory’ (也就是该导出项的名称)的字符数,并接下来的6个数字表示了 ‘memory’ 字符的ASCII编码。02 表示导出条目是一个内存索引(memory index➡️),而后面的 00 是实际的索引值。
综上,我们正在导出”Memory section”中的第一个内存向量,并将其命名为 memory。宿主环境可以与模块中的内存进行交互,通过名称 memory 引用内存。
Following the same rule to process the rest, we will get a function exported named fib, which points to the index 0 of the Function section, and the same with main.
根据相同的规则处理其他导出,我们可以得到一个名为fib的导出函数,它指向”Function section”的索引0,而main也是类似的,指向”Function section”的索引1。
Start
“Start section”(起始函数部分),包含一个起始函数索引。类似于C中的main函数。在WebAssembly实例化了模块之后,它就会执行这个起始函数。“Start section”的ID是8。内容就是一个u32表示的function index。
Element
表的初始内容是未初始化的,它可以使用元素段(Element segments)来从静态元素数组进行初始化。元素段是WebAssembly中的一种机制,它允许初始化表的子范围,将静态元素存储在表中。
一旦元素被加载到表中,就可以使用”CALL_INDIRECT”操作来间接调用表中的函数。
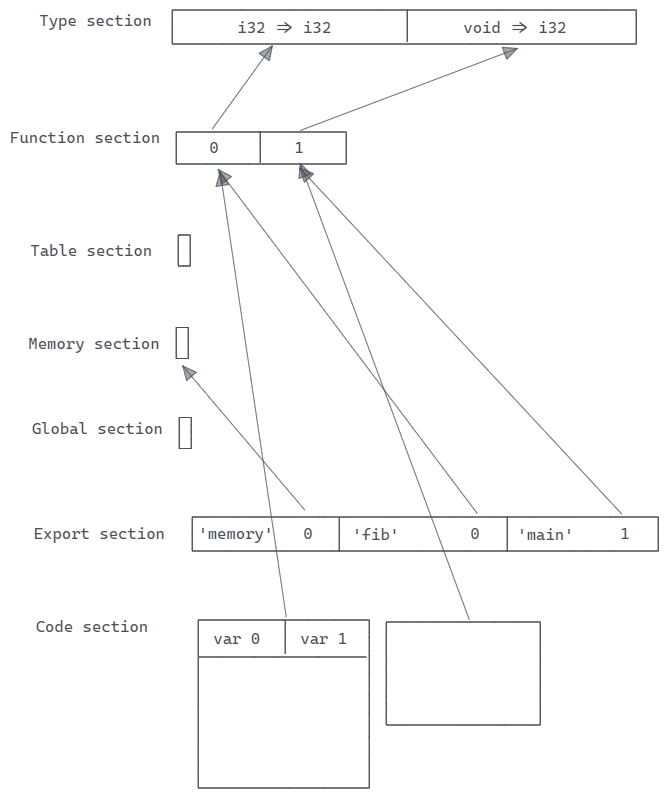
Code
“Code section”(代码部分)包括一个代码条目的数组,这些条目是值类型数组和表达式的组合。它们表示模块组件中函数的局部变量和主体字段。
具体来说,每个函数在WebAssembly模块中都有一个与之相关的代码条目,其中包括:
-
局部变量:局部变量是函数内部声明的变量,在函数体内部使用,存储函数计算中的临时数据。
-
函数体:函数体由一系列表达式组成,这些表达式是WebAssembly的指令(instruction),用于实现函数的操作和逻辑。
00000050 00 04 6d 61 69 6e 00 01 0a d7 80 80 80 00 02 c6 |..main..........|
^ ^ ^ ^ ^ ^ ^ ^
00000060 80 80 80 00 01 02 7f 41 01 21 02 02 40 20 00 41 |.......A.!..@ .A|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
00000070 01 72 41 01 46 0d 00 20 00 41 7e 6a 21 00 41 01 |.rA.F.. .A~j!.A.|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
00000080 21 02 03 40 20 00 41 01 6a 10 00 20 02 6a 21 02 |!..@ .A.j.. .j!.|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
00000090 20 00 41 01 72 21 01 20 00 41 7e 6a 21 00 20 01 | .A.r!. .A~j!. .|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
000000a0 41 01 47 0d 00 0b 0b 20 02 0b 86 80 80 80 00 00 |A.G.... ........|
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
000000b0 41 05 10 00 0b |A....|
^ ^ ^ ^ ^
“Code section”的ID为10。02 表示将有两个函数定义。c6 80 80 80 00 指示了第一个函数定义的体积大小(70)。然后,指定了局部变量,它们以(数量,类型)的方式进行分组。01 表示只有一种类型的变量,而 02 7f 表示两个 i32 类型的变量(这是唯一的局部变量类型,因为只有一个局部变量类型)。其余的字节(体积大小减去局部变量占用的字节)是指令。
上面的例子中,第一个函数有两个 i32 类型的局部变量,而第二个函数没有局部变量。
Epilogue
Yay, 我们成功解析了一个WebAssembly二进制文件的结构🎉!在下一个博客中,将介绍这些部分如何在运行时组合在一起,以实现WebAssembly模块的执行和功能。
Appendix
Fib in C
我用于编译wasm的C代码。
int fib(int n) {
if(n == 0 || n == 1) return 1;
return fib(n-1) + fib(n-2);
}
int main() {
return fib(5);
}